Protecting your content sources from bad actors, crawlers, and bots
When building your digital experiences at Arc XP, customer developers are provided with powerful ways to extend the Arc XP platform. Particularly, PageBuilder allows you to bring your own code, presentation features, and powerful content handling model with content sources. Content sources are responsible for organizing your data fetch, caching, and serving your experiences at scale. Customer developers can orchestrate content authoring, platform APIs, as well as bring third-party content into Arc XP using content sources.
This article is two-part series about content source security. See Preventing sensitive information leakage in your content sources.
PageBuilder and Arc XP Delivery have multiple layers of cache as a shield to your downstream APIs. Additionally, Web Application Firewall protects you from common attacks like DDoS, and anomaly detection shields your code and Arc XP system stability from bad actors. But despite those protections, bad actors can still find workarounds and impose security risks.
This article covers these known risks along with mitigation strategies and best practices to prevent these risks.
Overwhelming the render stack with cache busting
Unexpected traffic volumes can overwhelm the render stack. These traffic volumes can come in the form of unexpected bots and crawlers unintentionally overwhelming the stack or bad actors actively searching for vulnerabilities can overwhelm the render stack. This disruption can occur either at the PageBuilder resources or downstream in the APIs that your content sources orchestrate—both in Arc XP APIs or third-party APIs. Typically, this occurs in the form of cache busting or horizontally large amounts of uncache content being requested.
Bot and crawlers
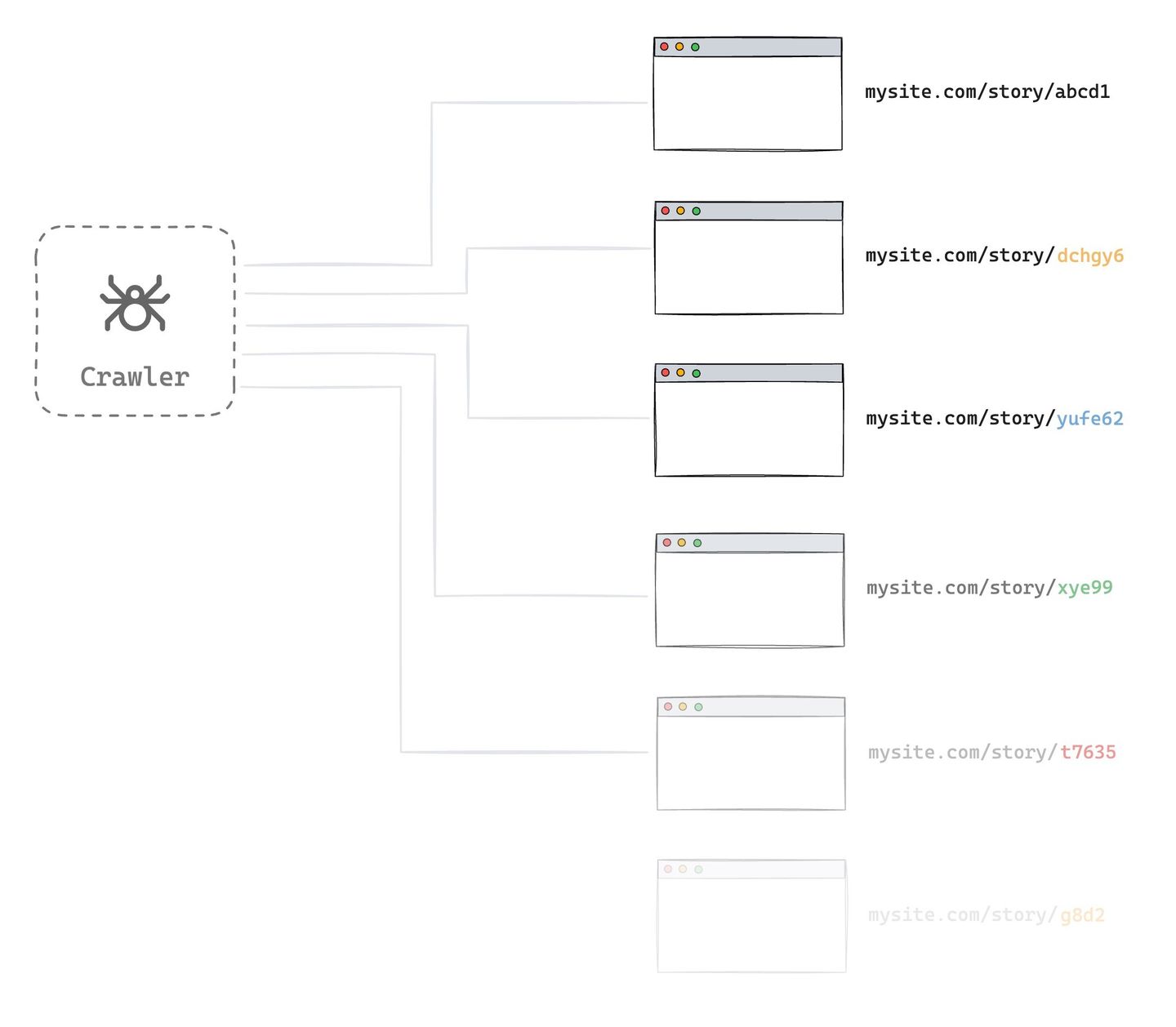
Bots and crawlers are expected consumers of content-based digital experiences. Search engines operates with sophisticated crawlers. Content-based businesses welcome these known crawlers. You may receive unexpected volume of traffic from unrecognized crawlers that may cause high volume of uncached renders to overwhelm the system.
These crawlers want to read as much content as they can without knowing the render stack’s limits. Or its' developers haven’t considered or aren’t concerned about the impact. Another common scenario for these crawlers is attempting to read old and archived content that is not receiving much traffic, which falls under the “uncached renders” case where it causes more content source and render volume.
 |
Bad actors
Bad actors can also use crawler-like scripts, but not for the sake of reading the content like search engines. Instead, bad actors use many resources, which overwhelms the system. Bad actor volume is similar to a DDoS attack, but they don’t necessarily have to be in extreme volumes.
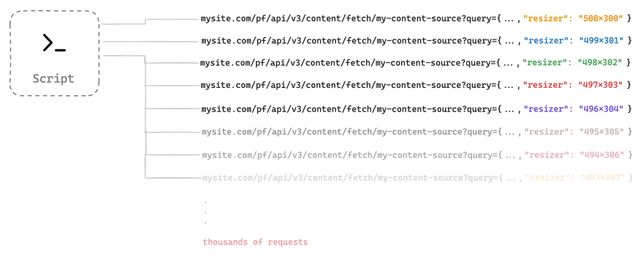
Oftentimes, bad actors discover the content source API calls (/pf/api/content/fetch) with finding a parameter that accepts a wide-range of enumerated values and sends the calls at a relatively high volume. Their goal is to bypass multiple layers of the Arc XP cache (CDN and Engine) and cause either of the systems to become overwhelmed. When the render systems start throttling requests, the actual user render requests begin to fail as well.
Here is an example how an HTTP request gets constructed from your feature custom fields:
GET /pf/api/v3/content/fetch/my-content-source?query=%7B%22feature%22%3A%22top-stories-list%22%2C%22offset%22%3A0%2C%22query%22%3A%22type%3Astory%22%2C%22size%22%3A5%2C%22resizer_size%22%3A%22500x300%22%7D HTTP/1.1
If we URL decode this request URL:
GET/pf/api/v3/content/fetch/my-content-source?query={"feature":"top-stories-list","offset":0,"query":"type:story","size":5,"resizer_size":"500x300"}HTTP/1.1You can see the PageBuilder serializes all custom field values into a JSON serialized object. If we format the JSON object that is serialized and pass in a "query" parameter:
{
"feature": "top-stories-list",
"offset": 0,
"query": "type:story",
"size": 5,
"resizer_size": "500x300"
}
Two parameters in this example are dangerous: "query" and "resizer_size". Both parameters are widely defined, possibly not validated in the content source code, and can be highly open to enumeration. This article covers open query parameters and their risk of sensitive information leakage in the following section, but let's look at simpler example between these two parameters: the resizer size. To visualize an example of enumerated variations of valid request URL, they may look like this:
 |
Parameter enumeration
Enumeration is a process where a bad actor performs a large amount of requests to gain information about the system they are attacking. Bad actors perform enumeration primarily to search for vulnerabilities or to extract information from target systems.
Essentially, enumeration is trying at scale. What we mean by trying is that bad actors try various combinations of request parameters to explore their targets. This article focuses on the side effect of enumeration, which when your system becomes overwhelmed by bad actor attacks.
Let’s look at how enumeration impacts Arc XP systems. The following diagram illustrates where the Arc XP render stack can fail when it becomes overwhelmed by enumeration.
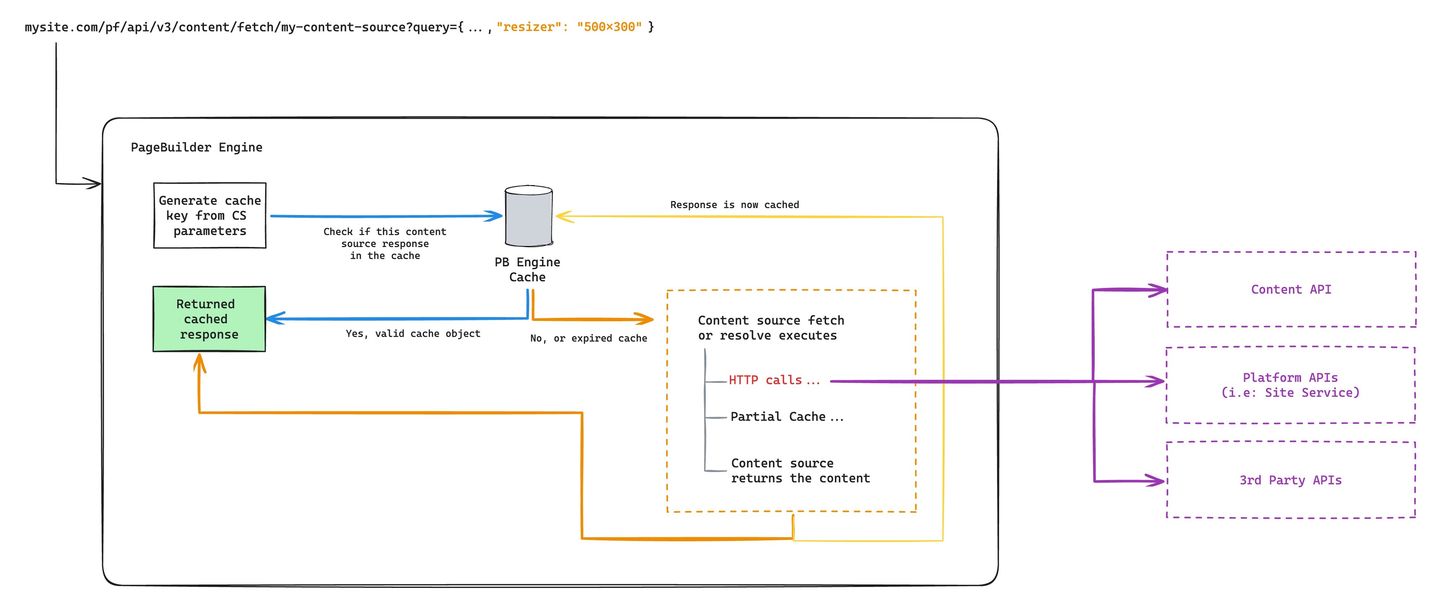 |
The blue path is the path that most of your real readers follow when a content source executes. The orange path is when the full content source execution takes place.
The two scenarios that we explained previously (crawlers and bad actors) both cause capacity limits to occur at your downstream API requests (from the orange box to purple boxes), essentially hitting uncached content source requests at large volume, skipping CDN and Engine cache, and resulting in a large volume of downstream HTTP/API calls in your content sources. The Arc XP CDN and PageBuilder stack can scale to very high volume of traffic rapidly and can adopt your readers' traffic trends. But downstream APIs are much more limited to their scale, often with fixed rate limits. This is the primary reason that the Arc XP render stack has two layers of cache to control the traffic scale.
Your developers must consider tactics to deflect these unexpected content source volumes. We focus on introducing additional layers of controls and checks up until before HTTP/API calls start executing (the red text in the diagram). This is the point where the render-dependent systems begin reaching their capacities and start retuning 429 rate limit errors.
Attacks and the reader experience
When your render system becomes overwhelmed, it can affect the content experience of your real readers. In most cases, even though real render requests fail to respond on the back end, the Arc XP CDN continues to serve the last successful renders from the CDN cache to your users for up to 72 hours.
The CDN’s job is to deliver the content in various conditions, including failure scenarios at the expense of content freshness. 72 hours is Arc XP’s default, and it can be increased if you can tolerate longer periods of times and want more resiliency. Your readers continue to receive content successfully without noticing any outage. The real risk here is not total failure to serve your readers, but to fail to serve fresh content. For example, if your newsroom staff actively publishes new content, the updates are delayed longer than usual. The new articles may fail to appear, given the bad actors continue to overwhelm the system.
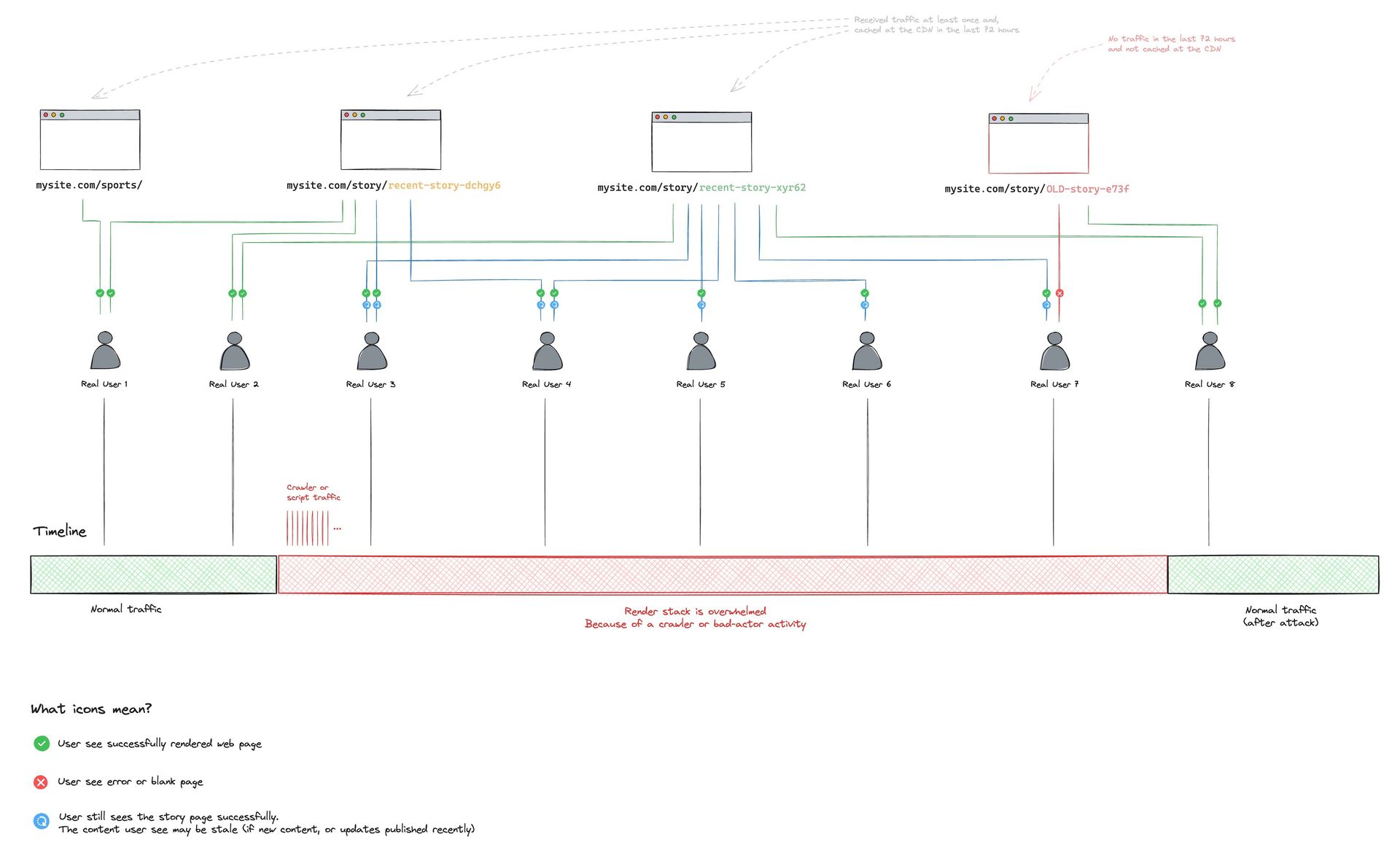 |
This diagram describes a timeline of an attack that causes the render stack to become overwhelmed and how the Arc XP CDN continues to serve your content to your readers. Given the majority of your real users are consuming recent content and the scale of your sites' traffic already covers a large surface area for your important content already cached within the 72-hour window, you almost always have successfully cached pages for your real users at any given time. Even though re-renders continue to happen every 2, 5, and 15 minutes, in the case of render stack failures, the Arc XP CDN continues to operate resiliently to serve your readers without disruption.
Arc XP Customer Support
Arc XP actively monitors these behaviors. Our team notices spikes of render activity, cache behavior changes, and downstream Content API load for a specific site. We analyze traffic patterns, and we continuously adjust the CDN systems to deflect bad actors, unknown bots, and crawlers. But depending on bad actors' persistence, monitoring for these behaviors can be time consuming and may cause disruption to your newsroom, technical staff, your readers, and Arc XP support teams.
It's important for your developers to be aware of these risks and take preventative measures.
Strategies to mitigate security attacks in your content sources
Use the following methods to harden your content sources against these type of attacks.
Use .http=false
Determine if a content source should use a sever-side render or a client-side content refresh.
Does this content source need to be public?
When does a content source can be private, or public? Can it be private, and only used on server-side render?
PageBuilder Engine has the capability to let you control if a content source is exposed as an API endpoint or not. By default, all your features are rendered isomorphically. That means they are rendered on both server-side render as well as client-side re-renders (hydrated). On the client-side render, if the content used to render that particular feature has expired, PageBuilder calls its back-end APIs to refresh the content. You can learn more about render modes in Rehydration vs. Server-Side vs. Client-Side (SPA) Rendering.
If there is no need for client-side render, you could make it fully server-side. To do that, add the .http property to your content source definition before exporting it in your code, and set the value of it to false. See Content Source API documentation.
When changing content source visibility, it’s important to keep another PageBuilder feature, Static, in mind. When a content source is paired with a Static feature, content source responses are used only in server-side render runtime. That means the response object of that content source does not make it to server-side render, or it does not cause any /pf/api calls. In this case, you can make a content source server-side only. If a content source is changed to become private-only; you must ensure all calls from features should be Statically served; otherwise, the client-side render breaks for the instances of the features that use this content source, and it still renders dynamically on the client-side.
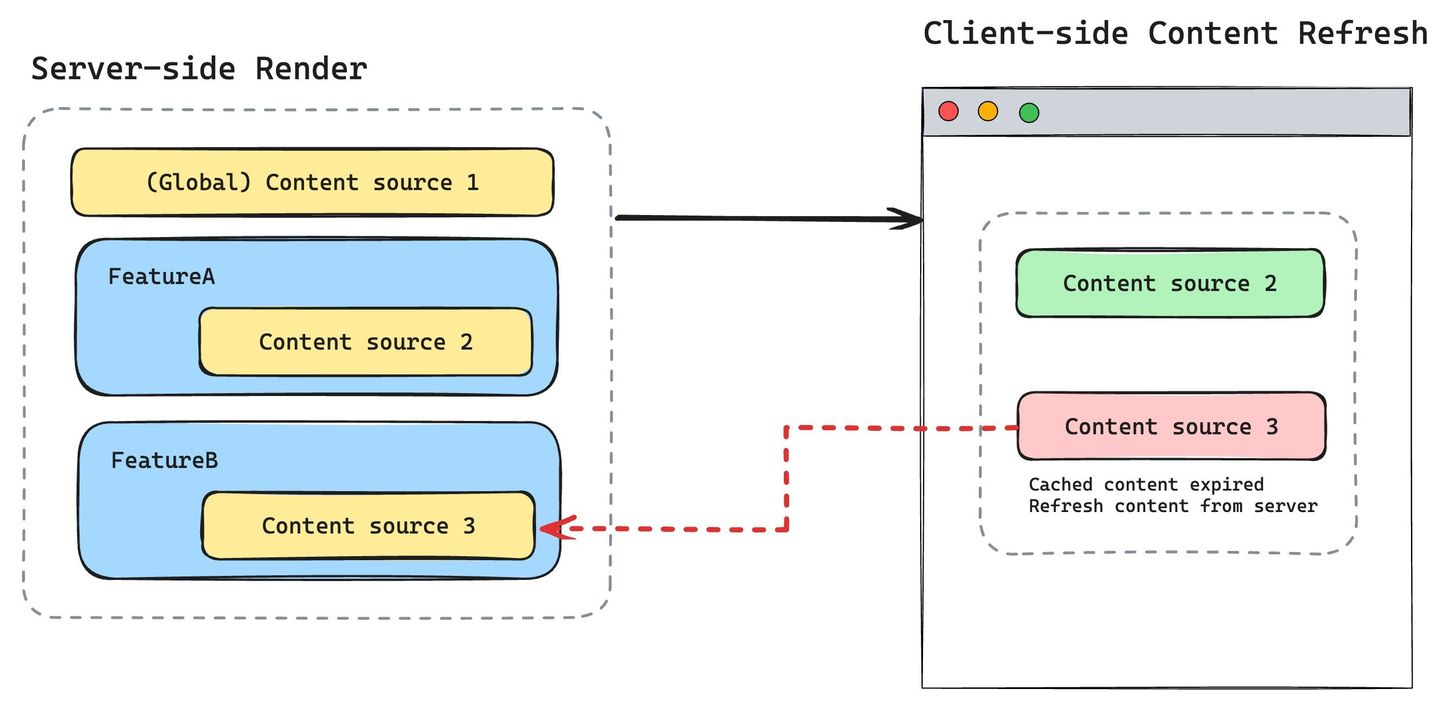 |
When setting http=false, beware that the content source becomes fully private from all API calls to PageBuilder Engine, including Debugger tools, as well as non-PageBuilder consumers if you utilize /pf/api endpoints in third-party applications. The most common scenario is consuming these endpoints from a mobile app or a back-end system. These are acceptable use cases, but when switching an existing content source to http=false, this process impacts these scenarios.
Use .strict=true
We talked about how important the “request” (or input) parameters for a content source are. PageBuilder Engine has an opt-in parameter for Content Source objects that lets you enforce parameter sanitation before cache-key gets generated.
By default, everything passed from the HTTP call within the query object gets used in cache key generation. And cache-key is a crucial part of how many requests the cache responds to quickly without executing the actual content source logic. If a bad actor or a crawler can enumerate the parameters, they can inject almost anything to the query object.
The most simple strategy is to enable .strict=true and make sure you define all parameters in the params object that a content source works with. Anything that is not recognized gets ignored before the cache-key gets generated. This minimizes the enumeration opportunities for a bad actor. It doesn’t completely eliminate them, but it minimizes then and helps you narrow down your content source inputs.
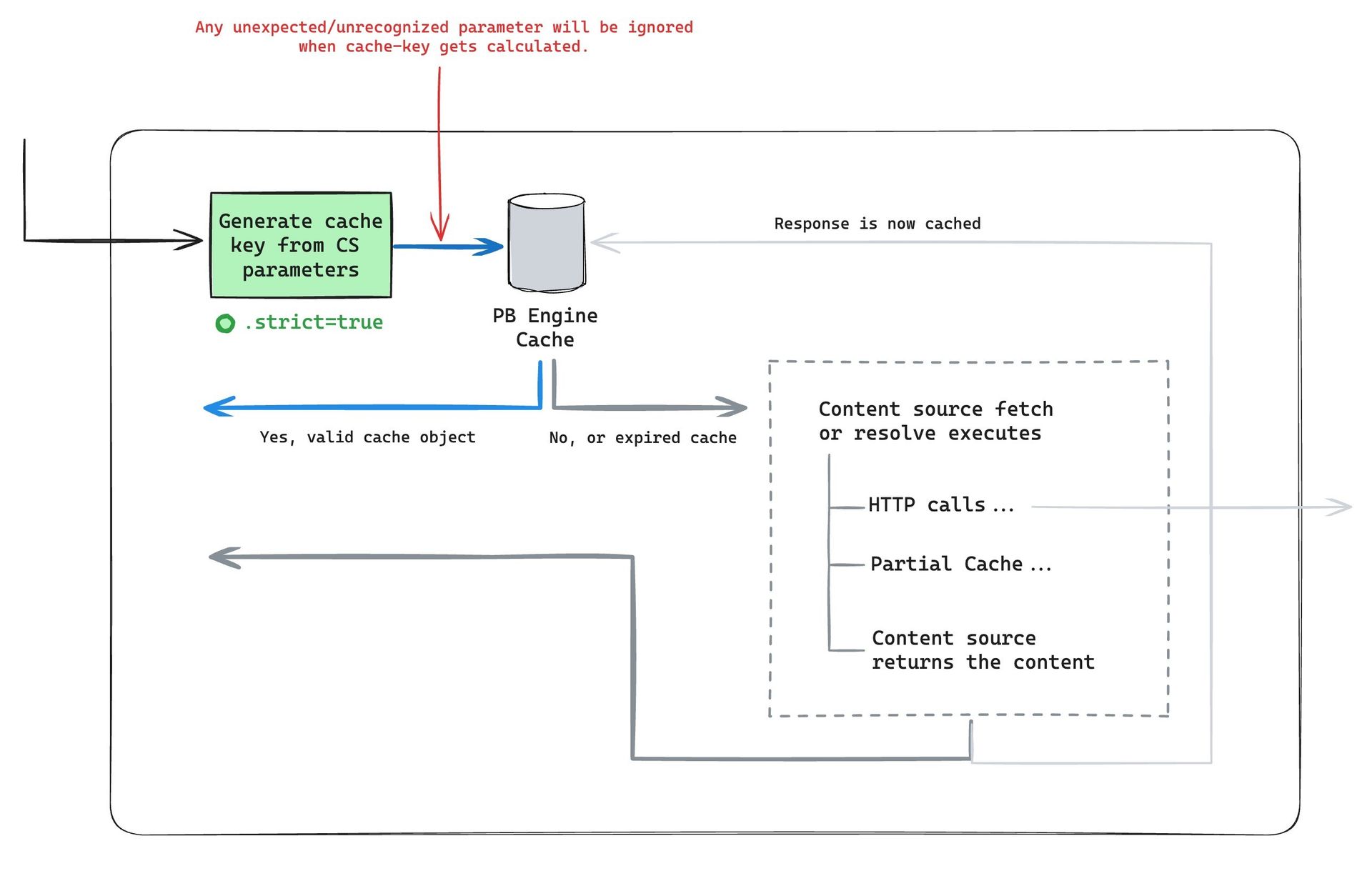 |
You can read more about strict property and how to use it in Content Source documentation.
Implement your own parameter validation, beyond “type checks”
In some cases, doing simple parameter and type recognization (with .strict=true) is not enough. You can harden your content source parameters even further by implementing parameter validation at the top of your content source before the HTTP requests gets executed.
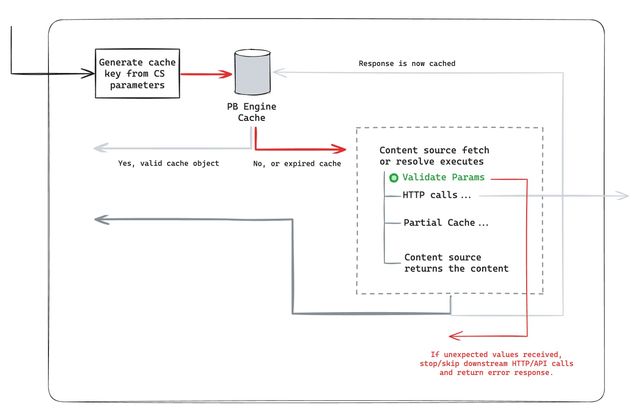 |
Clients often create or use a helper method to do schema and value validation to ensure the incoming content source parameters (and values) are expected and are valid.
Again, this does not catch every enumeration scenario, but it can narrow it even further to much more predictable values.
Design intentional content source parameters
In a web form, each field (including hidden fields) deserves deliberate consideration. Consider when readers will complete them, who completes them, and what are the expected values. More importantly, do the values need to be open, could they be dangerous formats, or are they a simple checkbox or drop-down option format. A best practice is to create fields with as narrow responses as possible. Avoid open, large, ambiguous values.
Let’s look at two examples (that we gave as examples in the bad actors section previously) to explain and demonstrate how to intentionally and more narrowly define two example parameters.
Example 1: Resizer image dimensions
A bad actor notices an image dimension as a string value (for example, 500x300) in one of the parameters, and they can generate thousands of valid, unique values for them. They can very easily create a Shell script to start hitting these URLs.
Most likely, you don’t need an open parameter value, and instead, you can use only handful of predefined sizes for your front-end.
const possibleResizerSizes = {
"hero": "1000x400"
"large": "800x600"
"medium": "400x300"
"small": "200x150"
"thumb": "100x40"
}
Even though auditing and defining all combinations in the code may sound strict and hardcoding the developer flexibility that requires deployment when a new image size gets introduced may seem cumbersome, it’s the secure thing to do. Even better, you can name these dimensions and provide a more simple drop-down experience to your editorial staff when they curate pages and work on feature configurations in PageBuilder Editor.
Your parameter in the API call may look like this instead:
mysite.com/pf/api/v3/content/fetch/my-content-source?query={..., "resizer": "large"}
You can easily validate this parameter in your content source and reject anything unexpected.
Example 2: Raw query as the content source parameter
The same example we gave includes a parameter called query.
{
"feature": "top-stories-list",
"offset": 0,
"query": "type:story",
"size": 5,
"resizer_size": "500x300"
}
This is an Arc XP Content API call to the /search endpoint. This endpoint allows developers to run any Elasticsearch search query and returns a list of stories. It is designed very generically, and you can use the endpoint in many ways. While it provides this flexibility, it also inherits risks to allow bad actors to interact with it if not carefully controlled in content sources.
In this example, the query value looks simple: type:story. However, the following risks exist for bad actors to exploit this content source:
Bad actors can explore all kinds of content in your organization. All it takes is for them to continue trying different combinations of possible content types, like photo, video, author, tag, or redirect, which are not difficult to discover. In this approach, we’re not mainly concerned about the sensitivity of the information, because almost all of these data types and what Content API returns is your content, and your intent is likely to make it publicly available.
Although you may have content that you are not intending to expose publicly (like draft articles), and bad actors can still use this exploit to get private information. For tips on preventing sensitive information leaks, see Preventing sensitive information leakage in your content sources.
This example resembles with SQL injection attacks. Consider this as you giving SQL access to bad actors. They can run a lot of queries to just explore your data freely. More dangerously, depending on the data sources you’re letting them interact with, they can be harmful with write capabilities, although PageBuilder works with automated access tokens that get generated in each deployment and are restricted read-only tokens to Arc XP APIs, and there are no write risks. The write risk is more applicable to the same design when you integrate with third-party APIs.
The main concern is the volume the bad actor generates to overwhelm the Elasticsearch stack, which stops impacting your real requests. You can use the Elasticsearch query string for enumeration, even if it returns the same responses.
In the SQL injection point we made in a previous bullet point, you can apply
1=1in the common SQL injection queries here, similar to an Elasticsearch query statement (for example,1:1). This alone is enough for enumeration.
How to mitigate query parameters?
Don’t define and use open parameters. Similar to the resizer example previously, your content source is most likely used in a finite amount of places, and/or your editorial staff has a finite amount of combinations for how they use your content sources in PageBuilder Editor. Pre-defining a set of these possible queries and defining this parameter as enum/dropdown also improves the PageBuilder Editor experience for your content source parameters.
{
...
"query": "type:story",
...
}
This can become:
{
...
"content_type": "stories",
...
}
with a pre-defined, expected values configuration, which you can validate on every request. If you receive an invalid value, you can stop executing your content sources because that is an unexpected request, and most likely a bad actor or a crawler is attempting variations on your content sources.
const possibleQueries = {
"stories": "type:story",
"featured_stories": "type:story AND taxonomy.primary_section.name:featured",
...
// Also can be templatized and accepts separate content source parameter
"stories_by_author": "type:story AND credits.by._id:%ATHOR_ID%",
...
}
Use partial caching
The underlying theme of the suggestions in this article is protecting your downstream API activity from the public traffic changes. One of the effective methods to shield downstream APIs independent from the upstream volume is to use partial caching within content sources. Partial caching is a PageBuilder Engine capability that allows you to wrap your business logic and API calls inside content sources to group them and control cache windows separate from the parent content sources.
Partial caching is used for various use cases, including controlling a specific API’s call volume across content sources, so it can be used as a shared cache. But more importantly, you can control the cache key generation parameters for partial cache calls.
This means you have one more layer where your developers can control what dynamic values constitute different API calls, and these calls get cached at the lower level inside content sources before the actual API calls are executed to downstream services.
A benefit to using partial caching is an optimized execution speed of content sources. For example, if you have three services you orchestrate together in a content source, without partial caching, all three services are executed at the same time. But you can isolate each API call and/or group them in partially cached calls. This way, you can control each one of them to be cached at different TTLs.
Tell me more, with an example
For example, let’s say your content source uses Google Analytics APIs to retrieve the most-read (top pageview) articles under a section (for example, /sports/story/*), and then uses the URI of those top stories to query content-api. Without partial caching, your content source may first call a Google Cloud Platform API to refresh its authentication token. When it receives a fresh token, the content source initiates a second call to Google Analytics API to get the most-read stories. Then finally, it can make the Arc XP Content API call. But what if you know that your refresh token from Google Cloud Platform is valid for one day.
Do you need to make that API call in every content-source execution? Probably not. You also don’t want to increase your parent content source’s TTL up to a day, because you want a refreshed list pf most-read stories. You can wrap the authentication API call with predictable parameters, which generate the same cache key every time, you set the TTL of that partial cache to one day, and you leave the rest at default or smaller TTLs.
import axios from 'axios'
const fetch = async ({ 'arc-site': arcSite }, { cachedCall }) => {
try {
const topPostsAPIUrl = 'https://google-analytics-api.com/pageviews?url=/posts/*'
const topPosts = await cachedCall(
'top-story', // content source name
() => axios(topPostsAPIUrl), // child fetch function
{
query: topPostsAPIUrl, // Will be used to generate partial cache-key
independent: true,
ttl: 60 * 60 * 1000 // 1 hour
}
)
const topPostId = topPosts[0].id
const postsResponse = await axios(`https://jsonplaceholder.typicode.com/posts/${topPostId}`)
const post = postsResponse.data
return {
title: post.title,
body: post.body
}
}
catch (error) {
throw new Error('Content fetch error')
}
}
export default {
fetch
}
This way your authentication-related downstream API call is both protected from a large volume of uncached content source executions and it retrieves cached tokens much faster. Almost all of your content source executions increase in speed. One bonus effect is, if you perform the same API call in multiple content sources, they can all use the same cached object across multiple content sources, thereby optimizing execution speed even further with shared-partial-cache.
Beware of sensitive information leakage
One of the biggest motivations for bad actors creating and using crawlers to seek information is to find private, sensitive, or unpublished information. Your content sources most likely use the Arc XP content platform as its source (although not required). It’s important for your developer team to be aware of the possible private, internal information that resides in your ANS objects.